Are you curious about what a data lake is and how it can benefit your organization? At WHAT.EDU.VN, we provide clear and concise answers to all your questions, including those related to data lakes, data warehouses, and data lakehouses, empowering you to unlock the potential of your data. Discover how a data lake can centralize your data, improve analytics, and drive better decision-making, and remember, if you ever have any questions, WHAT.EDU.VN is here to provide free and reliable answers. Data storage, data analytics, and big data solutions.
1. Understanding the Core of a Data Lake
A data lake is a centralized repository that allows you to store all your structured, semi-structured, and unstructured data at any scale. You can store your data as-is, without first structuring the data to fit a specific schema, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
1.1. The Fundamental Definition
A data lake is a vast storage repository that holds a massive quantity of raw data in its native format until it is needed. Data lakes are ideal for organizations that want to store all their data in one place, regardless of its source or format. This includes structured data from relational databases (like SQL databases), semi-structured data (like CSV files, logs, and XML data), and unstructured data (like emails, documents, PDFs, images, audio, and video).
1.2. Why Is It Called a Data Lake?
The term “data lake” is used because, like a natural lake, it contains a diverse collection of elements from various sources, all coexisting in their natural state. This contrasts with a data warehouse, where data is structured and refined before being stored, much like a reservoir. Data lakes are often implemented on low-cost object storage, such as Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage (GCS).
1.3. Key Characteristics of a Data Lake
- Centralized Repository: A data lake serves as a single, central location for all data within an organization.
- Raw Data Storage: Data is stored in its native format, without the need for upfront transformation.
- Scalability: Data lakes can scale to accommodate vast amounts of data.
- Flexibility: Supports a wide variety of data types and analytics workloads.
- Cost-Effective: Utilizes low-cost storage solutions.
1.4. Data Lake Architecture
A typical data lake architecture includes the following components:
- Data Ingestion: The process of bringing data into the lake from various sources.
- Storage: The scalable storage layer where data is stored in its raw format.
- Processing: The compute resources used to transform and analyze the data.
- Governance: The policies and processes used to manage and secure the data.
- Consumption: The tools and applications used to access and analyze the data.
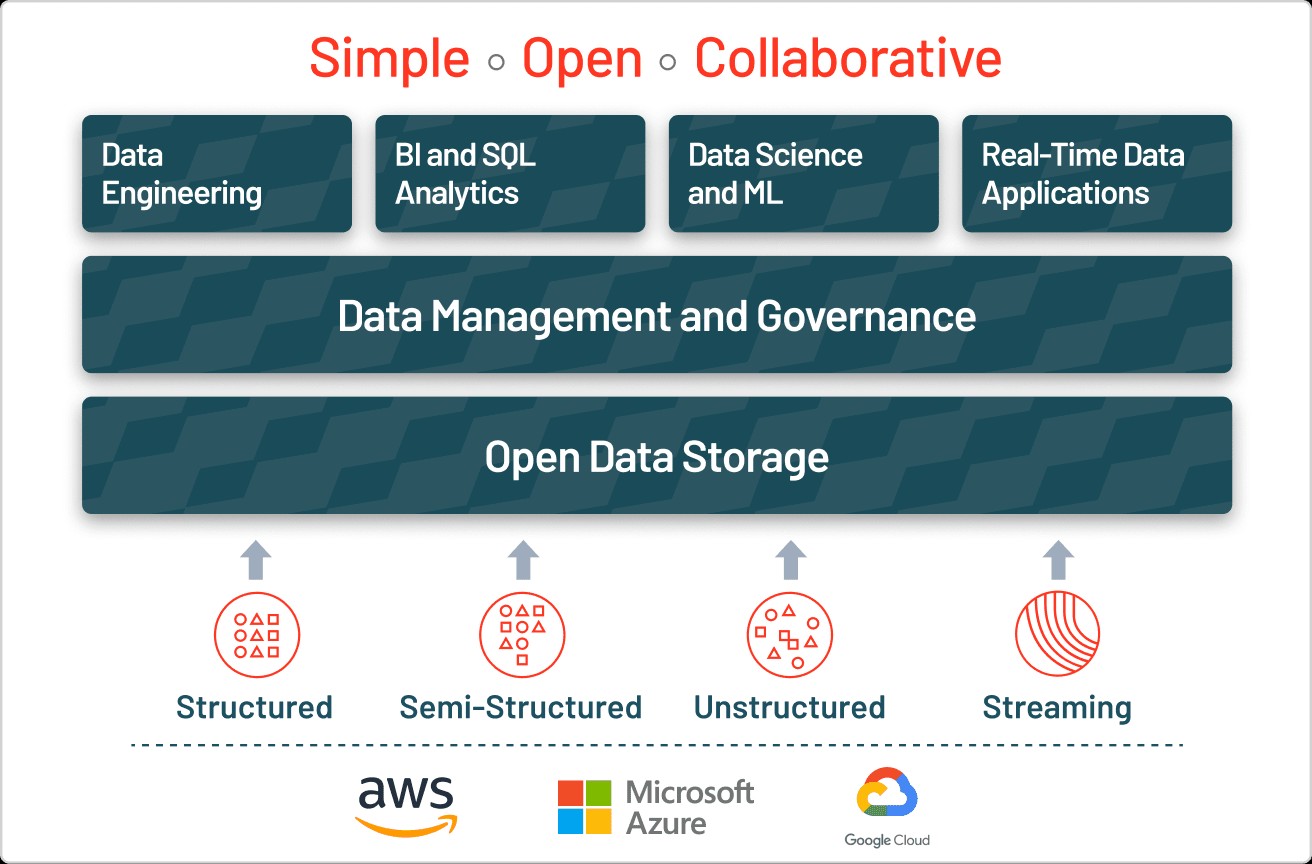
2. The Evolution: Data Lake vs. Data Warehouse vs. Data Lakehouse
Understanding the differences between a data lake, a data warehouse, and a data lakehouse is crucial for choosing the right architecture for your organization’s needs. Each has its own strengths and weaknesses, and the best choice depends on the specific use cases and requirements.
2.1. Data Lake vs. Data Warehouse: A Detailed Comparison
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data Types | Structured, semi-structured, and unstructured | Structured |
| Schema | Schema-on-read (schema is applied when the data is read) | Schema-on-write (schema is defined before data is loaded) |
| Storage Cost | Low | High |
| Scalability | Highly scalable | Limited scalability |
| Users | Data scientists, data engineers | Business analysts |
| Use Cases | Advanced analytics, machine learning, data discovery | Reporting, business intelligence |
| Flexibility | Very flexible | Less flexible |
2.2. Data Warehouse Explained
A data warehouse is a repository for structured, filtered data that has already been processed for a specific purpose. Data warehouses are optimized for Online Analytical Processing (OLAP) workloads and are designed to provide fast query performance for reporting and business intelligence.
2.3. Data Lakehouse: The Best of Both Worlds
A data lakehouse is a new architectural approach that combines the best aspects of data lakes and data warehouses. It provides the scalability and flexibility of a data lake with the data management and performance capabilities of a data warehouse.
2.4. Why Choose a Data Lakehouse?
The lakehouse architecture offers several advantages:
- Support for All Data Types: Handles structured, semi-structured, and unstructured data.
- Unified Governance: Provides consistent governance and security across all data.
- Cost Efficiency: Leverages low-cost storage options.
- Real-Time Analytics: Supports real-time and streaming analytics workloads.
- Machine Learning: Enables advanced machine learning and AI applications.
3. Benefits of Implementing a Data Lake
Implementing a data lake can provide numerous benefits for organizations across various industries. From improved analytics to enhanced decision-making, a data lake can unlock the full potential of your data.
3.1. Enhanced Analytics Capabilities
A data lake allows you to perform a wide variety of analytics, including:
- Descriptive Analytics: Understanding what happened in the past.
- Diagnostic Analytics: Determining why something happened.
- Predictive Analytics: Forecasting what might happen in the future.
- Prescriptive Analytics: Recommending actions to take.
3.2. Improved Decision-Making
By providing a comprehensive view of all data, a data lake enables better-informed decision-making across the organization. Business users can access the data they need, when they need it, to make more effective decisions.
3.3. Increased Agility and Flexibility
Data lakes allow organizations to quickly adapt to changing business needs and market conditions. The flexibility of a data lake makes it easy to ingest new data sources and explore new analytics use cases.
3.4. Cost Savings
By utilizing low-cost storage solutions and eliminating the need for upfront data transformation, a data lake can significantly reduce the cost of data management and analytics.
3.5. Support for Innovation
Data lakes provide a sandbox environment for data scientists and analysts to experiment with new data sources and analytics techniques. This can lead to innovative insights and new business opportunities.
4. Key Use Cases for Data Lakes
Data lakes are used across a wide range of industries and applications. Here are some of the most common use cases:
4.1. Customer Analytics
Organizations use data lakes to gain a deeper understanding of their customers by analyzing data from various sources, including:
- CRM Systems: Customer relationship management data.
- Marketing Automation Platforms: Data on marketing campaigns and customer engagement.
- Social Media: Data on customer sentiment and brand perception.
- E-Commerce Platforms: Data on customer purchases and browsing behavior.
4.2. IoT Analytics
The Internet of Things (IoT) generates vast amounts of data from sensors and devices. Data lakes provide a scalable and cost-effective solution for storing and analyzing this data to:
- Monitor Equipment Performance: Identify potential maintenance issues.
- Optimize Operations: Improve efficiency and reduce costs.
- Develop New Products and Services: Create innovative solutions based on IoT data.
4.3. Fraud Detection
Data lakes can be used to detect fraudulent activities by analyzing patterns and anomalies in data from various sources, including:
- Financial Transactions: Identify suspicious transactions.
- Insurance Claims: Detect fraudulent claims.
- Cybersecurity Logs: Identify potential security threats.
4.4. Healthcare Analytics
Healthcare organizations use data lakes to improve patient care and reduce costs by analyzing data from:
- Electronic Health Records (EHR): Patient medical history and treatment information.
- Medical Devices: Data from wearable sensors and medical equipment.
- Insurance Claims: Data on healthcare costs and utilization.
4.5. Supply Chain Optimization
Data lakes can be used to optimize supply chain operations by analyzing data from:
- Inventory Management Systems: Data on stock levels and demand.
- Transportation Management Systems: Data on shipping routes and delivery times.
- Supplier Data: Information on supplier performance and reliability.
5. Building a Data Lake: Best Practices
Building a successful data lake requires careful planning and execution. Here are some best practices to follow:
5.1. Define Clear Business Goals
Before you start building a data lake, it’s important to define clear business goals and use cases. This will help you prioritize your efforts and ensure that the data lake delivers value to the organization.
5.2. Choose the Right Technology Stack
Select a technology stack that meets your specific needs and requirements. Consider factors such as:
- Storage: Choose a scalable and cost-effective storage solution.
- Processing: Select a compute engine that can handle your analytics workloads.
- Data Governance: Implement tools and processes for managing and securing the data.
5.3. Implement a Robust Data Governance Framework
Data governance is essential for ensuring the quality, security, and compliance of the data in your data lake. Implement a framework that includes:
- Data Catalog: A centralized repository for metadata.
- Data Lineage: Tracking the flow of data from source to destination.
- Data Quality Monitoring: Monitoring the accuracy and completeness of the data.
- Access Control: Controlling who can access the data.
5.4. Automate Data Ingestion and Transformation
Automate the process of ingesting and transforming data to reduce manual effort and ensure consistency. Use tools such as:
- ETL Tools: Extract, transform, and load data from various sources.
- Data Integration Platforms: Integrate data from different systems.
- Workflow Automation Tools: Automate data processing tasks.
5.5. Monitor and Optimize Performance
Continuously monitor the performance of your data lake and optimize it for your specific workloads. Use tools such as:
- Performance Monitoring Tools: Track the performance of your data lake.
- Query Optimization Tools: Optimize the performance of your queries.
- Resource Management Tools: Manage the resources used by your data lake.
6. Overcoming Data Lake Challenges
While data lakes offer numerous benefits, they also present some challenges. Here are some common challenges and how to overcome them:
6.1. Data Swamp
A data swamp occurs when a data lake becomes disorganized and difficult to use. To prevent this, implement a robust data governance framework and ensure that data is properly cataloged and documented.
6.2. Data Quality Issues
Poor data quality can undermine the value of a data lake. Implement data quality monitoring and validation processes to ensure that data is accurate and complete.
6.3. Security Risks
Data lakes can be vulnerable to security threats if not properly secured. Implement strong access controls, encryption, and auditing to protect the data.
6.4. Lack of Skills
Building and managing a data lake requires specialized skills. Invest in training and development to ensure that your team has the skills they need.
6.5. Integration Challenges
Integrating data from various sources can be complex. Use data integration tools and techniques to simplify the process and ensure that data is consistent.
7. Data Lake Technologies and Tools
A wide range of technologies and tools are available for building and managing data lakes. Here are some of the most popular:
7.1. Storage Solutions
- Amazon S3: A scalable and cost-effective object storage service.
- Azure Data Lake Storage (ADLS): A cloud-based storage solution optimized for big data analytics.
- Google Cloud Storage (GCS): A highly durable and scalable storage service.
- Hadoop Distributed File System (HDFS): A distributed file system for storing large datasets.
7.2. Processing Engines
- Apache Spark: A fast and versatile data processing engine.
- Apache Hadoop MapReduce: A programming model for processing large datasets.
- Presto: A distributed SQL query engine for big data.
- Apache Flink: A stream processing framework for real-time analytics.
7.3. Data Integration Tools
- Apache Kafka: A distributed streaming platform for building real-time data pipelines.
- Apache NiFi: An easy-to-use data integration tool for automating the flow of data.
- Talend: A comprehensive data integration platform.
- Informatica PowerCenter: A widely used ETL tool.
7.4. Data Governance Tools
- Apache Atlas: A metadata management and governance tool.
- Collibra: A data governance platform for managing data assets.
- Alation: A data catalog and data intelligence platform.
- Informatica Axon: A data governance and data quality platform.
8. Real-World Examples of Data Lake Implementation
Many organizations have successfully implemented data lakes to gain a competitive advantage. Here are a few examples:
8.1. Netflix
Netflix uses a data lake to store and analyze data from various sources, including:
- Streaming Data: Data on what users are watching.
- User Profiles: Data on user demographics and preferences.
- Device Data: Data on the devices users are using to watch Netflix.
Netflix uses this data to personalize recommendations, improve streaming quality, and optimize content delivery.
8.2. Airbnb
Airbnb uses a data lake to store and analyze data from:
- Listings Data: Data on the properties listed on Airbnb.
- Booking Data: Data on bookings and reservations.
- User Data: Data on users and their preferences.
Airbnb uses this data to optimize pricing, improve search results, and enhance the user experience.
8.3. Capital One
Capital One uses a data lake to store and analyze data from:
- Customer Transactions: Data on customer spending habits.
- Credit Card Applications: Data on credit card applicants.
- Fraud Detection Systems: Data on potential fraud cases.
Capital One uses this data to improve customer service, detect fraud, and manage risk.
9. The Future of Data Lakes
The future of data lakes is bright, with new technologies and trends emerging that will further enhance their capabilities.
9.1. Rise of the Lakehouse
The lakehouse architecture is gaining popularity as organizations seek to combine the best aspects of data lakes and data warehouses.
9.2. AI-Powered Data Lakes
Artificial intelligence (AI) is being used to automate data governance, improve data quality, and enhance analytics in data lakes.
9.3. Real-Time Data Lakes
Real-time data lakes are becoming more common as organizations need to analyze data in real-time to respond to changing business conditions.
9.4. Cloud-Native Data Lakes
Cloud-native data lakes are being deployed on cloud platforms such as AWS, Azure, and Google Cloud to take advantage of the scalability and cost-effectiveness of the cloud.
9.5. Open Source Data Lakes
Open source technologies are playing an increasingly important role in data lakes, providing organizations with more flexibility and control over their data.
10. Frequently Asked Questions (FAQs) About Data Lakes
Here are some frequently asked questions about data lakes:
10.1. What is the difference between a data lake and a data mart?
A data mart is a subset of a data warehouse that is focused on a specific business area or department. A data lake, on the other hand, is a centralized repository for all data within an organization.
10.2. How do I choose the right storage solution for my data lake?
Consider factors such as scalability, cost, performance, and security when choosing a storage solution for your data lake.
10.3. What are the key considerations for data governance in a data lake?
Key considerations for data governance include data cataloging, data lineage, data quality monitoring, and access control.
10.4. How can I ensure the security of my data lake?
Implement strong access controls, encryption, and auditing to protect the data in your data lake.
10.5. What skills are needed to build and manage a data lake?
Skills needed to build and manage a data lake include data engineering, data science, data governance, and data security.
10.6. What are the common challenges of implementing a data lake and how can they be overcome?
Common challenges include data swamp, data quality issues, security risks, lack of skills, and integration challenges. These can be overcome by implementing a robust data governance framework, monitoring data quality, securing the data, investing in training, and using data integration tools.
10.7. How does a data lake support machine learning initiatives?
A data lake provides a centralized repository for the vast amounts of data needed for machine learning, allowing data scientists to easily access and explore the data.
10.8. Can a data lake replace a data warehouse?
A data lake can complement a data warehouse, but it is not a replacement. A data warehouse is optimized for reporting and business intelligence, while a data lake is optimized for advanced analytics and machine learning.
10.9. What are the best practices for data ingestion into a data lake?
Best practices for data ingestion include automating the process, validating the data, and ensuring that data is properly cataloged and documented.
10.10. How can I measure the success of my data lake?
Measure the success of your data lake by tracking key metrics such as:
- Data Quality: Accuracy and completeness of the data.
- Data Accessibility: Ease of access to the data.
- Data Usage: Number of users and applications accessing the data.
- Business Value: Impact of the data lake on business outcomes.
Here’s a helpful table summarizing these FAQs:
| Question | Answer |
|---|---|
| What is the difference between a data lake and a data mart? | A data mart is a subset of a data warehouse focused on a specific area; a data lake is a centralized repository for all organizational data. |
| How do I choose the right storage solution for my data lake? | Consider scalability, cost, performance, and security. |
| What are the key considerations for data governance in a data lake? | Data cataloging, data lineage, data quality monitoring, and access control. |
| How can I ensure the security of my data lake? | Implement strong access controls, encryption, and auditing. |
| What skills are needed to build and manage a data lake? | Data engineering, data science, data governance, and data security. |
| What are common challenges of implementing a data lake? | Data swamp, data quality issues, security risks, lack of skills, and integration challenges; overcome with governance, monitoring, training, and integration tools. |
| How does a data lake support machine learning initiatives? | It provides a centralized repository for large amounts of data, making it easily accessible for data scientists. |
| Can a data lake replace a data warehouse? | No, they complement each other. A data warehouse is for reporting, while a data lake is for advanced analytics and machine learning. |
| What are best practices for data ingestion into a data lake? | Automate the process, validate the data, and ensure proper cataloging and documentation. |
| How can I measure the success of my data lake? | By tracking data quality, accessibility, usage, and business value. |
11. Conclusion: Embracing the Power of Data Lakes
Data lakes are transforming the way organizations manage and analyze data. By providing a centralized repository for all data, data lakes enable better decision-making, increased agility, and support for innovation. While building and managing a data lake can be challenging, the benefits are well worth the effort. Embrace the power of data lakes and unlock the full potential of your data.
Remember, if you have any questions or need further assistance, visit WHAT.EDU.VN for free and reliable answers. Our team of experts is here to help you navigate the complex world of data management and analytics.
If you’re looking for a platform to ask any question and get free answers, WHAT.EDU.VN is your go-to resource. Our community is ready to provide you with the knowledge you need to succeed.
Don’t hesitate—visit WHAT.EDU.VN today and ask your question. Let us help you find the answers you’re looking for!
Address: 888 Question City Plaza, Seattle, WA 98101, United States.
Whatsapp: +1 (206) 555-7890.
Website: what.edu.vn
 Data Lake vs Data Lakehouse vs Data Warehouse Comparison
Data Lake vs Data Lakehouse vs Data Warehouse Comparison
Alt text: Comparison of data lake, data lakehouse, and data warehouse architectures, highlighting their differences in data types, cost, format, scalability, intended users, reliability, ease of use, and performance.