Transformer models are revolutionizing the field of artificial intelligence. They’re not the toys of your childhood or the electrical components you see on power poles. Instead, they are sophisticated neural networks at the heart of many AI applications you use every day. So, What Is A Transformer and why are they so important?
A transformer model is a type of neural network architecture that learns context and meaning by tracking relationships in sequential data. Think of it like this: when you read a sentence, you don’t just process each word in isolation. You understand the meaning by considering the relationships between the words and their context within the sentence. Transformers do the same thing, but with data.
They achieve this by using a set of mathematical techniques called “attention” or “self-attention.” These techniques allow the model to identify subtle dependencies between even distant data elements in a sequence.
First introduced in a groundbreaking 2017 paper by Google researchers, transformers have quickly become one of the most powerful classes of models available. They’re fueling a new wave of advancements in machine learning, often referred to as “transformer AI.”
Stanford researchers, in their August 2021 paper, even labeled transformers as “foundation models,” emphasizing their role in driving a paradigm shift in the field. The researchers stated that “the sheer scale and scope of foundation models over the last few years have stretched our imagination of what is possible.”
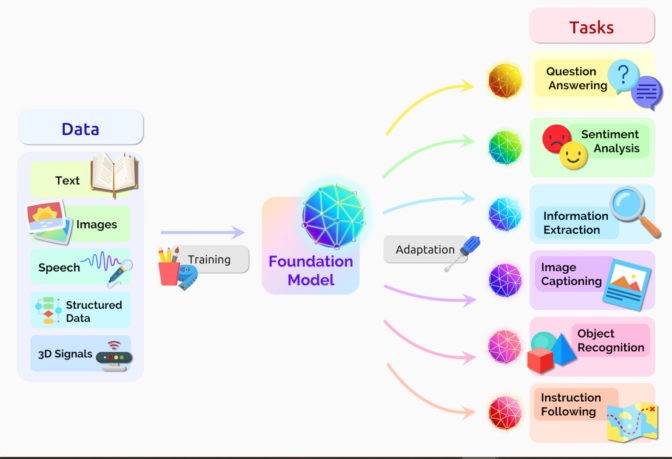
What Can Transformer Models Do?
The capabilities of transformer models are vast and expanding rapidly. They are already being used in a wide range of applications, including:
- Real-time Translation: Transformers are powering near real-time translation of text and speech, facilitating communication in diverse settings.
- Drug Discovery: Researchers are leveraging transformers to understand the complex relationships within DNA and proteins, accelerating the process of drug design.
- Fraud Detection: Transformers can detect trends and anomalies in data to prevent fraud and enhance security.
- Personalized Recommendations: Many online platforms use transformers to analyze user behavior and provide tailored recommendations.
- Improved Healthcare: Transformers are being used to extract valuable insights from clinical data, leading to advancements in medical research and patient care.
Image: A diverse set of transformer applications, showcasing their versatility across industries.
In essence, any application that relies on sequential data, such as text, image, or video, can benefit from the use of transformer models. Chances are, you are already interacting with transformers every time you use a search engine like Google or Bing.
The Virtuous Cycle of Transformer AI
Transformer models benefit from a positive feedback loop. They are trained on massive datasets, enabling them to make accurate predictions. As these models are deployed in more applications, they generate even more data, which can then be used to further improve their performance.
NVIDIA founder and CEO Jensen Huang highlighted this transformative shift in his keynote address at GTC, stating that “Transformers made self-supervised learning possible, and AI jumped to warp speed.”
Transformers Replace CNNs and RNNs
The rise of transformers has led to their adoption as the go-to architecture in many areas, even replacing previously dominant architectures like convolutional neural networks (CNNs) and recurrent neural networks (RNNs). Just five years ago, CNNs and RNNs were the most popular types of deep learning models.
The shift is evident in the research landscape. A staggering 70 percent of AI papers on arXiv published in the last two years mention transformers, marking a dramatic change from the past. A 2017 IEEE study reported that RNNs and CNNs were the most popular models for pattern recognition at that time.
No Labels, More Performance
One of the key advantages of transformers is their ability to learn from unlabeled data. Traditionally, training neural networks required large, meticulously labeled datasets, which were expensive and time-consuming to create. Transformers overcome this limitation by mathematically identifying patterns between data elements, allowing them to leverage the vast amounts of unlabeled data available on the web and in corporate databases.
Furthermore, the mathematical operations used in transformers are highly amenable to parallel processing, leading to faster training and inference times. This efficiency has allowed transformers to excel in performance benchmarks like SuperGLUE, a leading benchmark for language-processing systems.
How Transformers Pay Attention
Transformer models are based on an encoder-decoder architecture. However, the power of transformers lies in strategic additions to these blocks, primarily the “attention mechanism.”
Image: A simplified diagram illustrating the core components of a transformer model, including attention mechanisms.
Here’s how it works:
- Positional Encoding: Data elements entering the network are tagged with positional encoders, providing information about their location in the sequence.
- Attention Units: These units analyze the tagged data elements and calculate a map that represents the relationship between each element and all other elements in the sequence. This calculation often involves parallel processing through “multi-headed attention,” which uses multiple sets of equations to capture diverse relationships.
Self-Attention Finds Meaning
Self-attention allows the model to understand the nuances of language and meaning. Consider these sentences:
- She poured water from the pitcher to the cup until it was full.
- She poured water from the pitcher to the cup until it was empty.
In the first sentence, “it” refers to the cup, while in the second sentence, “it” refers to the pitcher. Humans easily understand this distinction based on context. Self-attention enables computers to achieve a similar level of understanding.
Ashish Vaswani, who led the work on the seminal 2017 transformer paper, explains that “Meaning is a result of relationships between things, and self-attention is a general way of learning relationships. Machine translation was a good vehicle to validate self-attention because you needed short- and long-distance relationships among words. Now we see self-attention is a powerful, flexible tool for learning.”
The Future of Transformers
Transformers are rapidly evolving. Researchers are exploring larger models with trillions of parameters, as well as techniques to create more efficient and simpler models. The goal is to develop models that can learn from context with very little data, much like humans do.
The development of safe and responsible models is also a key focus. This includes addressing issues such as bias and toxicity to ensure that these powerful tools are used ethically and responsibly.
In conclusion, what is a transformer? It is more than just a neural network; it’s a revolutionary architecture that is transforming the landscape of artificial intelligence. With its ability to learn context, process data efficiently, and adapt to a wide range of applications, the transformer model is poised to play an increasingly important role in shaping the future of AI.
