HA: High Availability Explained by WHAT.EDU.VN is designed to maintain continuous operation, even when failures occur. It’s a critical concept, especially in today’s always-on digital landscape. Learn what HA means, its importance, and how it works. Find the answers you need regarding system uptime and resilience with WHAT.EDU.VN.
1. Defining High Availability (HA)
High Availability (HA) refers to a system’s ability to operate continuously for a specified period, even if components within the system fail. A highly available system achieves an agreed-upon level of operational performance by eliminating single points of failure. This is accomplished through the inclusion of redundant components that act as backups and can take over processing if a failure occurs. In essence, HA ensures that critical systems remain operational, minimizing downtime and maintaining business continuity.
Think of HA as a safety net for your critical systems. Just as a trapeze artist relies on a net to prevent injury in case of a fall, organizations rely on HA to ensure their systems remain operational, even when unexpected failures occur.
2. Key Principles of High Availability
Several key principles underpin the design and implementation of HA systems:
- Redundancy: This involves duplicating critical components, such as servers, storage, and network devices, so that if one component fails, another can immediately take over.
- Failover: This is the automatic switching of a workload to a backup component when the primary component fails. Failover mechanisms are essential for minimizing downtime and ensuring continuous operation.
- Monitoring: Continuous monitoring of system health and performance is crucial for detecting failures and triggering failover procedures. Monitoring tools provide real-time insights into system behavior, allowing administrators to identify and resolve issues before they impact users.
- Testing: Regular testing of failover procedures is essential to ensure that they work as expected. Testing helps to identify and address potential problems before they occur in a production environment.
3. The Importance of High Availability
High availability is paramount in scenarios where system downtime can have severe consequences. Consider these examples:
- Healthcare: In healthcare, HA systems are crucial for ensuring that doctors and nurses have access to patient records and medical equipment at all times. Downtime can delay treatment, leading to adverse patient outcomes.
- Finance: Financial institutions rely on HA systems to process transactions, manage accounts, and prevent fraud. Downtime can disrupt financial markets and lead to significant financial losses.
- Telecommunications: Telecommunication networks rely on HA systems to maintain connectivity and ensure that calls and data transmissions are not interrupted. Downtime can disrupt communication services and impact businesses and individuals.
- E-commerce: Online retailers rely on HA systems to process orders, manage inventory, and provide customer service. Downtime can lead to lost sales and damage to brand reputation.
In these and many other scenarios, the cost of downtime can be substantial, making HA a critical investment.
4. High Availability vs. Fault Tolerance
While both HA and fault tolerance aim to minimize downtime, they differ in their approach and level of protection.
- High Availability: HA focuses on minimizing downtime by providing redundant components that can take over when a failure occurs. HA systems typically experience some downtime during failover, but the goal is to keep this downtime to a minimum.
- Fault Tolerance: Fault tolerance aims to eliminate downtime altogether by providing redundant components that operate in parallel. If one component fails, the other continues to operate seamlessly, without any interruption in service.
Fault tolerance offers a higher level of protection than HA, but it is also more complex and expensive to implement. Fault-tolerant systems are typically used in mission-critical applications where downtime is unacceptable, such as air traffic control and nuclear power plants.
5. High Availability and Disaster Recovery
High availability and disaster recovery (DR) are complementary strategies for ensuring business continuity.
- High Availability: HA focuses on preventing downtime due to local failures, such as server crashes or network outages.
- Disaster Recovery: DR focuses on restoring systems and data after a catastrophic event, such as a natural disaster or a cyberattack.
HA and DR work together to provide comprehensive protection against a wide range of potential disruptions. HA ensures that systems remain operational during local failures, while DR ensures that they can be restored quickly and efficiently after a major disaster.
6. Achieving High Availability: Key Steps
Achieving high availability requires a comprehensive approach that encompasses system design, implementation, and ongoing management. Here are some key steps:
6.1. Designing for High Availability
The first step in achieving HA is to design systems with HA in mind. This involves:
- Identifying critical components: Determine which components are essential for system operation and prioritize their protection.
- Eliminating single points of failure: Identify and eliminate any single points of failure that could cause the entire system to go down.
- Incorporating redundancy: Implement redundancy for critical components, such as servers, storage, and networks.
- Implementing failover mechanisms: Implement automatic failover mechanisms that can quickly switch to backup components when a failure occurs.
6.2. Implementing High Availability
Once the system is designed for HA, the next step is to implement the necessary hardware and software components. This may involve:
- Deploying redundant hardware: Installing redundant servers, storage devices, and network equipment.
- Configuring failover software: Configuring software that automatically detects failures and initiates failover procedures.
- Setting up monitoring tools: Implementing monitoring tools that continuously track system health and performance.
6.3. Testing High Availability
After implementing HA, it is essential to test the system thoroughly to ensure that it works as expected. This involves:
- Simulating failures: Simulating various types of failures, such as server crashes and network outages, to test the failover mechanisms.
- Verifying failover: Verifying that failover occurs automatically and that the backup components take over seamlessly.
- Measuring downtime: Measuring the amount of downtime experienced during failover to ensure that it meets the required levels.
6.4. Monitoring and Maintaining High Availability
Achieving HA is not a one-time effort. It requires ongoing monitoring and maintenance to ensure that the system continues to operate at the required levels. This involves:
- Continuous monitoring: Continuously monitoring system health and performance to detect potential problems.
- Regular testing: Regularly testing failover procedures to ensure that they continue to work as expected.
- Periodic maintenance: Performing periodic maintenance tasks, such as software updates and hardware replacements, to keep the system running smoothly.
7. High Availability Best Practices
In addition to the steps outlined above, there are several best practices that can help organizations achieve HA:
- Use a layered approach: Implement HA at multiple layers of the system, including the hardware, operating system, and application layers.
- Automate failover: Automate failover procedures as much as possible to minimize downtime.
- Use load balancing: Use load balancing to distribute traffic across multiple servers, preventing any single server from becoming overloaded.
- Implement data replication: Implement data replication to ensure that data is always available, even if a storage device fails.
- Monitor performance: Continuously monitor system performance to identify and resolve potential bottlenecks.
- Test regularly: Test failover procedures regularly to ensure that they work as expected.
- Keep software up to date: Keep software up to date with the latest security patches and bug fixes.
- Document procedures: Document all HA procedures clearly and concisely.
- Train staff: Train staff on HA procedures and responsibilities.
8. High Availability in the Cloud
Cloud computing offers several advantages for achieving HA. Cloud providers typically offer:
- Redundant infrastructure: Cloud providers have redundant infrastructure in place, including multiple data centers and redundant network connections.
- Automatic failover: Cloud providers offer automatic failover mechanisms that can quickly switch to backup resources when a failure occurs.
- Scalability: Cloud resources can be scaled up or down as needed, providing flexibility and resilience.
- Cost-effectiveness: Cloud computing can be more cost-effective than building and maintaining on-premises HA systems.
By leveraging cloud computing, organizations can achieve HA more easily and cost-effectively.
9. Common High Availability Architectures
Several common architectures are used to implement high availability:
- Active-Passive: In this architecture, one server is active and handles all traffic, while the other server is passive and waits in standby mode. If the active server fails, the passive server takes over.
- Active-Active: In this architecture, both servers are active and handle traffic simultaneously. Load balancing is used to distribute traffic across the servers. If one server fails, the other server continues to handle all traffic.
- Clustering: Clustering involves grouping multiple servers together to act as a single system. If one server in the cluster fails, the other servers continue to operate, providing continuous service.
- Replication: Replication involves copying data from one server to another. If the primary server fails, the backup server can take over, providing access to the data.
The choice of architecture depends on the specific requirements of the application and the desired level of availability.
10. High Availability Monitoring Tools
Several tools are available to monitor the health and performance of HA systems:
- Nagios: Nagios is a popular open-source monitoring tool that can monitor servers, applications, and network devices.
- Zabbix: Zabbix is another open-source monitoring tool that offers a wide range of features, including alerting, reporting, and trend analysis.
- Datadog: Datadog is a cloud-based monitoring tool that provides real-time insights into system performance.
- New Relic: New Relic is a cloud-based monitoring tool that focuses on application performance.
- Amazon CloudWatch: Amazon CloudWatch is a monitoring service provided by Amazon Web Services (AWS).
- Microsoft Azure Monitor: Microsoft Azure Monitor is a monitoring service provided by Microsoft Azure.
- Google Cloud Monitoring: Google Cloud Monitoring is a monitoring service provided by Google Cloud Platform (GCP).
These tools can help organizations identify and resolve potential problems before they impact users.
11. Understanding Availability Metrics
Availability is often measured using metrics such as:
- Uptime: The percentage of time that a system is operational.
- Downtime: The amount of time that a system is unavailable.
- Mean Time Between Failures (MTBF): The average time between system failures.
- Mean Time To Recovery (MTTR): The average time it takes to recover from a system failure.
These metrics can be used to track the performance of HA systems and identify areas for improvement.
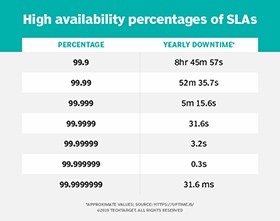
12. Service Level Agreements (SLAs) and High Availability
Service Level Agreements (SLAs) are contracts between service providers and customers that define the level of service to be provided, including availability. SLAs typically specify the minimum uptime percentage that the service provider guarantees.
For example, an SLA might guarantee 99.99% availability, which means that the system will be available for at least 99.99% of the time. If the service provider fails to meet the SLA, the customer may be entitled to compensation.
13. High Availability Case Studies
Numerous organizations have successfully implemented HA systems to improve their business operations. Here are a few examples:
- Amazon: Amazon uses HA systems to ensure that its e-commerce website is always available to customers.
- Google: Google uses HA systems to ensure that its search engine and other online services are always available.
- Facebook: Facebook uses HA systems to ensure that its social networking website is always available to users.
- Netflix: Netflix uses HA systems to ensure that its streaming video service is always available to subscribers.
- Salesforce: Salesforce uses HA systems to ensure that its customer relationship management (CRM) software is always available to customers.
These case studies demonstrate the value of HA in ensuring business continuity and customer satisfaction.
14. The Future of High Availability
High availability is an evolving field, with new technologies and approaches emerging all the time. Some of the key trends in HA include:
- Cloud-native HA: Cloud-native HA focuses on building HA systems that are specifically designed for cloud environments.
- AI-powered HA: AI-powered HA uses artificial intelligence to automate HA tasks, such as failure detection and failover.
- Edge HA: Edge HA focuses on providing HA for applications that run at the edge of the network, such as IoT devices and mobile devices.
These trends are driving the development of new HA solutions that are more resilient, scalable, and cost-effective.
15. Frequently Asked Questions (FAQs) about High Availability
| Question | Answer |
|---|---|
| What is the difference between high availability and fault tolerance? | High availability minimizes downtime, while fault tolerance eliminates it completely through redundant components operating in parallel. |
| How is availability measured? | Availability is measured using metrics like uptime percentage, downtime, MTBF, and MTTR. |
| What are some common HA architectures? | Common architectures include active-passive, active-active, clustering, and replication. |
| What are the benefits of using cloud computing for HA? | Cloud computing offers redundant infrastructure, automatic failover, scalability, and cost-effectiveness for HA. |
| What are some best practices for achieving HA? | Best practices include eliminating single points of failure, using load balancing, implementing data replication, and continuously monitoring performance. |
| How does disaster recovery relate to high availability? | High availability focuses on local failures, while disaster recovery addresses catastrophic events, both aiming to ensure business continuity. |
| What role do SLAs play in high availability? | SLAs define the minimum uptime percentage that a service provider guarantees, with potential compensation for failures to meet the agreed-upon level. |
| What tools can be used to monitor high availability systems? | Tools like Nagios, Zabbix, Datadog, New Relic, and cloud provider monitoring services can be used. |
| How can AI improve high availability? | AI can automate tasks like failure detection and failover, making HA systems more efficient and responsive. |
| Is high availability only for large enterprises? | No, high availability is beneficial for any organization that relies on critical systems and cannot afford downtime. The specific implementation will vary depending on the organization’s size and needs. |

16. Still Have Questions? Ask WHAT.EDU.VN!
Finding reliable answers to your questions shouldn’t be a struggle. At WHAT.EDU.VN, we understand the frustration of searching endlessly for clear, concise information. That’s why we’ve created a platform where you can ask any question, big or small, and receive answers from knowledgeable individuals, all for free.
16.1. Why Choose WHAT.EDU.VN?
- Free Access: Our platform is completely free to use. Ask as many questions as you like without any hidden costs.
- Fast Answers: Get prompt responses to your queries, so you can move forward with your projects and learning.
- Expert Knowledge: Benefit from the insights of a community of experts in various fields.
- Easy to Use: Our user-friendly interface makes it simple to ask questions and find the information you need.
16.2. How to Get Started
- Visit our website: WHAT.EDU.VN
- Type your question into the search bar.
- Submit your question and wait for our community to provide answers.
16.3. We’re Here to Help
At WHAT.EDU.VN, we’re committed to providing you with the best possible experience. If you have any questions or need assistance, please don’t hesitate to contact us:
- Address: 888 Question City Plaza, Seattle, WA 98101, United States
- WhatsApp: +1 (206) 555-7890
- Website: WHAT.EDU.VN
16.4. Don’t let unanswered questions hold you back!
Visit WHAT.EDU.VN today and get the answers you need to succeed. Our mission is to empower you with knowledge and make learning accessible to everyone.
Ask your question now and experience the WHAT.EDU.VN difference!
17. Additional Resources
To further expand your understanding of high availability, consider exploring these resources:
- Books: “High Availability: Design, Techniques, and Technologies” by Michael Stackpole
- Websites: The websites of major cloud providers, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), offer extensive documentation on HA.
- Industry publications: TechTarget, InfoQ, and other industry publications regularly publish articles and reports on HA.
18. Conclusion
High availability is a critical aspect of modern IT systems. By understanding the principles, techniques, and best practices outlined in this article, organizations can build systems that are resilient, reliable, and able to meet the demands of today’s always-on world. Remember, eliminating downtime is essential for maintaining business continuity, protecting revenue, and ensuring customer satisfaction. Visit what.edu.vn today for more insightful information and answers to all your questions.