Retrieval-augmented generation (RAG) in AI enhances the accuracy and reliability of generative AI models by fetching information from relevant data sources, and WHAT.EDU.VN is here to explain how. This technique fills the gaps in how large language models work, ensuring users get authoritative answers grounded in specific data. Explore how RAG boosts AI, making it more trustworthy and efficient with knowledge retrieval and contextual understanding.
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique that enhances generative AI models by providing them with information retrieved from external and relevant data sources. In essence, it bridges the gap in how large language models (LLMs) operate by supplementing their existing knowledge with specific, up-to-date information.
LLMs are neural networks that use parameters to represent patterns in human language, allowing them to respond to various queries. However, their pre-existing knowledge might not be sufficient for users seeking detailed or specialized information.
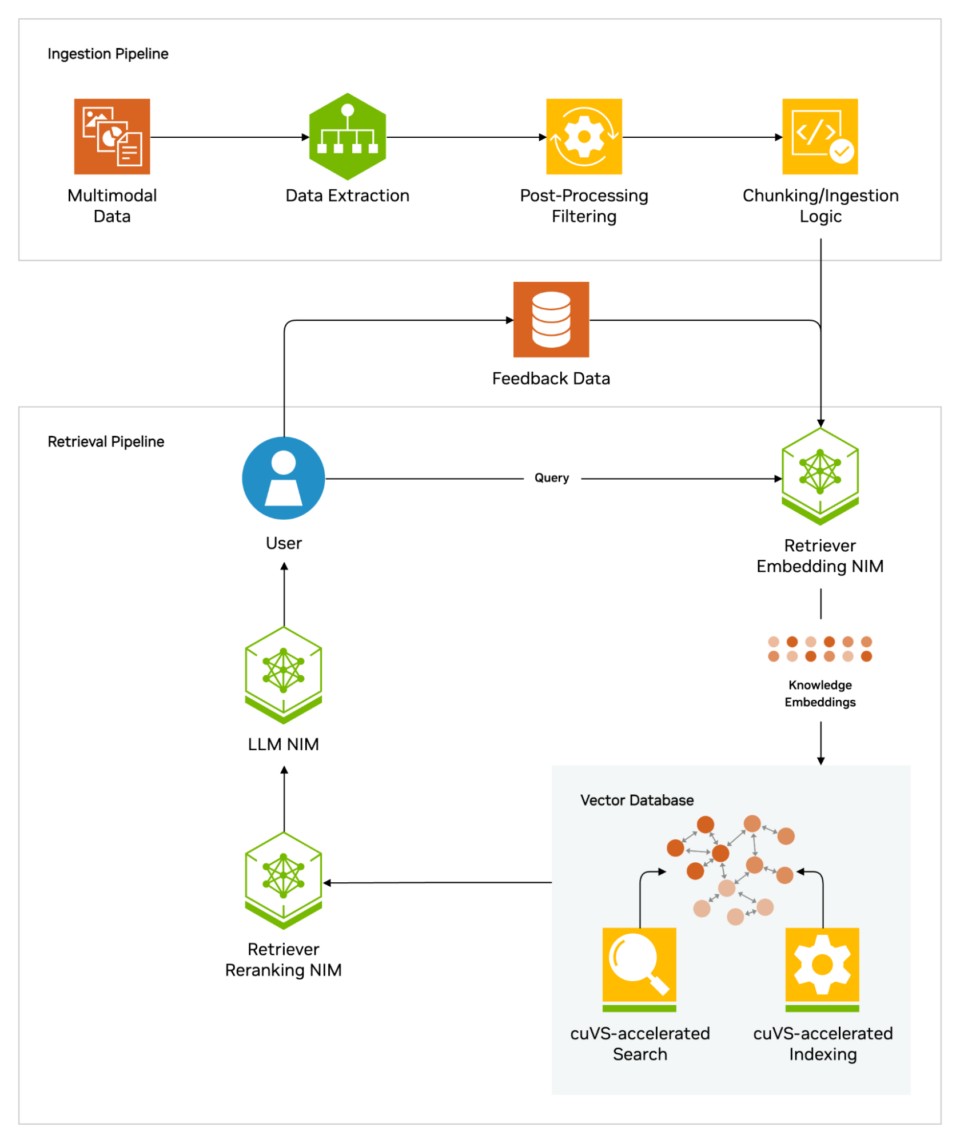 RAG model
RAG model
Alt text: Retrieval-augmented generation enhances LLMs by integrating embedding and reranking models and storing knowledge in a vector database for precise query retrieval.
2. Why is Retrieval-Augmented Generation Important?
Retrieval-augmented generation is crucial because it addresses the limitations of LLMs by:
- Enhancing Accuracy: By retrieving information from reliable sources, RAG ensures that the answers provided by AI models are accurate and contextually relevant.
- Building Trust: RAG provides sources that users can verify, similar to footnotes in a research paper, thereby increasing the trustworthiness of the AI-generated content.
- Reducing Hallucinations: RAG minimizes the likelihood of AI models producing incorrect or misleading information, a common issue known as hallucination.
- Enabling Specificity: RAG allows AI models to deliver detailed and specific answers, catering to users who require in-depth knowledge on particular subjects.
3. How Does Retrieval-Augmented Generation Work?
Retrieval-augmented generation works through a multi-step process that combines the strengths of LLMs with external knowledge retrieval:
- Query Input: A user poses a question to the LLM.
- Query Conversion: The AI model converts the query into a numeric format, also known as an embedding or vector, which machines can read.
- Data Retrieval: The embedding model compares the numeric values to vectors in a machine-readable index of an available knowledge base.
- Information Retrieval: When a match is found, the related data is retrieved and converted into human-readable words.
- Response Generation: The LLM combines the retrieved words and its own response to the query to produce a final answer, often citing the sources used.
- Index Updating: The embedding model continuously creates and updates machine-readable indices for new and updated knowledge bases.
This process ensures that the LLM has access to the most current and relevant information, allowing it to generate accurate and reliable responses.
4. What Are the Key Components of Retrieval-Augmented Generation?
The key components of retrieval-augmented generation include:
- Large Language Model (LLM): The core AI model responsible for generating responses.
- Embedding Model: Converts queries and data into numeric vectors for machine readability.
- Vector Database: A machine-readable index of available knowledge bases.
- Knowledge Base: The external data source containing the information to be retrieved.
- Retrieval Mechanism: The process of finding and extracting relevant information from the knowledge base.
These components work together to ensure that the LLM can access and utilize external knowledge effectively.
5. What Are the Benefits of Using Retrieval-Augmented Generation?
Using retrieval-augmented generation offers numerous benefits:
- Improved Accuracy: RAG ensures that AI-generated responses are based on reliable and up-to-date information.
- Enhanced Trustworthiness: By providing verifiable sources, RAG builds user trust in AI-generated content.
- Reduced Hallucinations: RAG minimizes the risk of AI models producing incorrect or misleading information.
- Increased Specificity: RAG allows AI models to deliver detailed and contextually relevant answers.
- Cost-Effectiveness: RAG is generally faster and less expensive than retraining an AI model with additional datasets.
- Flexibility: RAG enables users to easily swap new data sources on the fly, providing greater flexibility and adaptability.
6. What Are Some Real-World Applications of Retrieval-Augmented Generation?
Retrieval-augmented generation has a wide range of applications across various industries:
- Healthcare: Assisting doctors and nurses by providing access to medical indices and research.
- Finance: Supporting financial analysts with real-time market data and analysis.
- Customer Support: Enhancing customer service by providing access to technical and policy manuals.
- Employee Training: Facilitating employee training by providing access to training materials and resources.
- Developer Productivity: Improving developer productivity by providing access to documentation and code repositories.
These applications demonstrate the versatility and potential of RAG in enhancing AI-driven solutions across different sectors.
7. How Does Retrieval-Augmented Generation Compare to Fine-Tuning?
Retrieval-augmented generation and fine-tuning are two distinct methods for enhancing the performance of large language models (LLMs), each with its own set of advantages and use cases.
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Data Handling | Retrieves information from external knowledge bases at runtime. | Modifies the LLM’s internal parameters using a specific dataset. |
| Knowledge Base | Relies on external data sources that can be updated and changed dynamically. | Limited to the knowledge embedded in the fine-tuning dataset. |
| Implementation | Relatively easier and faster to implement, often requiring minimal code. | More complex and time-consuming, requiring significant computational resources. |
| Cost | Generally less expensive as it doesn’t require retraining the entire model. | Can be expensive due to the computational resources needed for retraining. |
| Flexibility | Highly flexible, allowing users to easily swap and update data sources. | Less flexible, as updating the model requires another round of fine-tuning. |
| Accuracy | Improves accuracy by grounding responses in specific, verifiable sources, reducing hallucinations. | Can improve accuracy, but the model is still limited to the knowledge it has learned during fine-tuning. |
| Trustworthiness | Enhances trustworthiness by providing sources and references that users can check. | Does not inherently provide sources or references, making it harder to verify the information. |
| Use Cases | Ideal for applications requiring up-to-date information and specific knowledge domains, such as customer support and research. | Best suited for tasks that require adapting the model to a specific style or format, such as content generation and sentiment analysis. |
| Examples | – Chatbots that provide real-time product information. | – Models trained to generate specific types of content (e.g., marketing copy). |
8. What Tools and Technologies Are Used in Retrieval-Augmented Generation?
Several tools and technologies are commonly used in retrieval-augmented generation:
- LangChain: An open-source library that helps chain together LLMs, embedding models, and knowledge bases.
- NVIDIA NeMo Retriever: Provides large-scale retrieval accuracy.
- NVIDIA NIM: Microservices for simplifying AI deployment.
- Vector Databases: Tools like Pinecone that store and manage vector embeddings for efficient retrieval.
- NVIDIA AI Enterprise: A software platform for accelerating AI development and deployment.
These tools and technologies streamline the implementation and optimization of RAG pipelines.
9. How Can Businesses Implement Retrieval-Augmented Generation?
Businesses can implement retrieval-augmented generation by following these steps:
- Identify Knowledge Bases: Determine the relevant data sources, such as technical manuals, policy documents, and customer support logs.
- Set Up Vector Databases: Implement a vector database to store and manage embeddings of the knowledge base.
- Choose an Embedding Model: Select an appropriate embedding model to convert queries and data into numeric vectors.
- Integrate with an LLM: Connect the retrieval system with a large language model to generate responses.
- Test and Optimize: Continuously test and optimize the system to ensure accuracy and relevance.
- Deploy and Monitor: Deploy the RAG system and monitor its performance to identify areas for improvement.
By following these steps, businesses can effectively leverage RAG to enhance their AI-driven solutions.
10. What Are the Challenges and Limitations of Retrieval-Augmented Generation?
While retrieval-augmented generation offers numerous benefits, it also has some challenges and limitations:
- Complexity: Setting up and maintaining a RAG system can be complex, requiring expertise in multiple areas.
- Scalability: Scaling RAG systems to handle large knowledge bases and high query volumes can be challenging.
- Data Quality: The accuracy and relevance of RAG depend on the quality of the underlying data sources.
- Latency: Retrieving information from external sources can introduce latency, affecting the speed of response generation.
- Cost: Implementing and maintaining RAG systems can incur costs related to infrastructure, tools, and expertise.
Addressing these challenges requires careful planning, robust infrastructure, and ongoing optimization.
11. How Does RAG Enhance the Trustworthiness of AI Systems?
RAG enhances the trustworthiness of AI systems by:
- Providing Sources: RAG provides users with verifiable sources, similar to footnotes in a research paper, allowing them to check the claims made by the AI model.
- Reducing Hallucinations: By grounding responses in specific and reliable data, RAG minimizes the risk of AI models producing incorrect or misleading information.
- Improving Accuracy: RAG ensures that AI-generated responses are based on the most accurate and up-to-date information available.
- Ensuring Transparency: RAG makes the reasoning process of AI models more transparent, allowing users to understand how the AI arrived at a particular answer.
These factors collectively contribute to building user trust in AI systems powered by RAG.
12. What Role Does Context Play in Retrieval-Augmented Generation?
Context plays a crucial role in retrieval-augmented generation. The ability to understand and utilize context ensures that the retrieved information is relevant and appropriate for the user’s query.
- Query Understanding: The AI model must understand the context of the user’s query to retrieve the most relevant information.
- Data Relevance: The retrieved data must be contextually relevant to the query to provide accurate and meaningful answers.
- Response Generation: The LLM must use context to generate responses that are coherent, informative, and aligned with the user’s intent.
- Ambiguity Resolution: Context helps resolve ambiguities in the query, ensuring that the AI model provides the most appropriate response.
By effectively leveraging context, RAG systems can deliver more accurate, relevant, and trustworthy information to users.
13. How Can RAG Be Used to Improve Customer Service?
RAG can significantly improve customer service by providing agents and chatbots with access to a wealth of relevant information:
- Quick Access to Information: Agents can quickly retrieve answers to customer queries from a centralized knowledge base.
- Consistent and Accurate Responses: RAG ensures that customers receive consistent and accurate responses, regardless of the agent or channel they interact with.
- Personalized Support: RAG can be used to personalize support by providing agents with customer-specific information and recommendations.
- Reduced Resolution Times: By providing agents with quick access to information, RAG can help reduce resolution times and improve customer satisfaction.
- 24/7 Availability: RAG-powered chatbots can provide 24/7 support, ensuring that customers can get help whenever they need it.
These capabilities make RAG a valuable tool for enhancing customer service operations.
14. What Are the Ethical Considerations of Using RAG in AI?
Using RAG in AI raises several ethical considerations:
- Data Privacy: Ensuring that the data used in knowledge bases is collected and used in compliance with privacy regulations.
- Bias: Mitigating the risk of bias in the data sources, which can lead to discriminatory or unfair outcomes.
- Transparency: Ensuring that users are aware of how RAG is being used and how it affects the responses they receive.
- Accountability: Establishing clear lines of accountability for the accuracy and reliability of the information provided by RAG systems.
- Misinformation: Preventing the spread of misinformation by ensuring that the data sources used in RAG are reliable and trustworthy.
Addressing these ethical considerations requires careful planning, robust governance, and ongoing monitoring.
15. What Future Trends Can We Expect in Retrieval-Augmented Generation?
Several future trends are expected to shape the evolution of retrieval-augmented generation:
- Integration with More LLMs: RAG will be increasingly integrated with a wider range of large language models, enhancing their capabilities and versatility.
- Advanced Retrieval Techniques: More advanced retrieval techniques, such as semantic search and graph-based retrieval, will be used to improve the accuracy and efficiency of RAG.
- Automated Knowledge Base Updates: Automated systems for updating and maintaining knowledge bases will become more prevalent, ensuring that RAG systems have access to the most current information.
- Personalized RAG: RAG systems will become more personalized, tailoring the retrieved information and responses to individual user needs and preferences.
- Edge Computing: RAG will be increasingly deployed on edge devices, enabling real-time information retrieval and response generation in a variety of settings.
These trends promise to further enhance the capabilities and applications of retrieval-augmented generation in the future.
16. How to Choose the Right Knowledge Base for RAG Implementation?
Selecting the appropriate knowledge base is critical for the success of a RAG implementation. Consider these factors:
- Relevance: The knowledge base should contain information directly relevant to the queries you expect.
- Accuracy: Ensure the information is accurate and up-to-date. Regularly audit and update the content.
- Coverage: The knowledge base should cover a broad range of topics within the relevant domain.
- Structure: A well-structured knowledge base facilitates easier and more efficient retrieval.
- Accessibility: The data should be easily accessible and compatible with the RAG system.
17. What Metrics Should Be Used to Evaluate a RAG System?
Evaluating the performance of a RAG system requires careful consideration of several metrics:
- Accuracy: Measures the correctness of the generated responses.
- Relevance: Assesses how relevant the retrieved information is to the user’s query.
- Completeness: Evaluates whether the response covers all relevant aspects of the query.
- Latency: Measures the time it takes to generate a response.
- User Satisfaction: Gathers feedback from users to assess their overall satisfaction with the system.
Regular monitoring of these metrics can help identify areas for improvement and ensure that the RAG system is meeting its objectives.
18. Can RAG Be Used With Multimodal Data?
Yes, RAG can be used with multimodal data, such as images, videos, and audio, in addition to text. This involves:
- Embedding Multimodal Data: Using specialized models to create embeddings for different data types.
- Storing Embeddings: Storing these embeddings in a vector database.
- Retrieving Relevant Data: Matching user queries with relevant multimodal data.
- Generating Responses: Integrating the retrieved multimodal data into the LLM’s response.
This capability extends the applicability of RAG to a wider range of use cases, such as image-based question answering and video summarization.
19. What is the Role of Vector Databases in RAG?
Vector databases are essential for RAG because they provide efficient storage and retrieval of vector embeddings. Their key roles include:
- Storing Embeddings: Storing high-dimensional vector representations of text and other data.
- Efficient Retrieval: Enabling fast similarity searches to find the most relevant data for a given query.
- Scalability: Handling large volumes of data and high query loads.
- Indexing: Providing indexing capabilities to optimize retrieval performance.
Popular vector databases include Pinecone, FAISS, and Annoy.
20. How Does RAG Help in Overcoming the Knowledge Cutoff Problem in LLMs?
One of the major limitations of LLMs is their knowledge cutoff, meaning they are unaware of information created after their last training update. RAG helps overcome this by:
- Accessing Real-Time Information: Allowing LLMs to access up-to-date information from external knowledge bases.
- Providing Current Data: Ensuring that the LLM’s responses are based on the latest available data.
- Dynamic Updates: Enabling dynamic updates of the knowledge base, so the LLM always has access to the most current information.
- Reducing Stale Responses: Minimizing the risk of the LLM providing outdated or irrelevant information.
By addressing the knowledge cutoff problem, RAG ensures that LLMs can provide accurate and timely responses to user queries.
Do you have more questions about RAG or other AI topics? Visit WHAT.EDU.VN today to ask your questions and get free, expert answers. Our platform is designed to provide you with quick, accurate, and easy-to-understand information. Contact us at 888 Question City Plaza, Seattle, WA 98101, United States. Whatsapp: +1 (206) 555-7890. Visit what.edu.vn and get the answers you need now.
